🧠 GPT-2 Processing Pipeline
1. Tokenization using Byte Pair Encoding (BPE)
GPT-2 splits input text into subword tokens using BPE.
Tokens: ["What", "Ġis", "Ġthe", "Ġcapital", "Ġof", "ĠFrance", "?"]
Token IDs: [2061, 318, 262, 3139, 286, 4881, 30]

2. Token IDs → Embedding Vectors
Each token ID is mapped to a dense vector (e.g., 768-dimensional for GPT-2 small).
Embedding size varies with model version.

3. Add Positional Encodings
Learned position vectors are added to token embeddings:
This adds sequence information to embeddings.

4. Transformer Decoder Blocks
GPT-2 applies multiple Transformer blocks, each with:
- Masked multi-head self-attention
- Feed-forward network (with GELU)
- Residual connections and layer normalization


5. Final Representation
The output of the last block is a contextualized vector for each token:

6. Next Token Prediction
Only the last token's output is used:
Then softmax is applied to get probabilities.

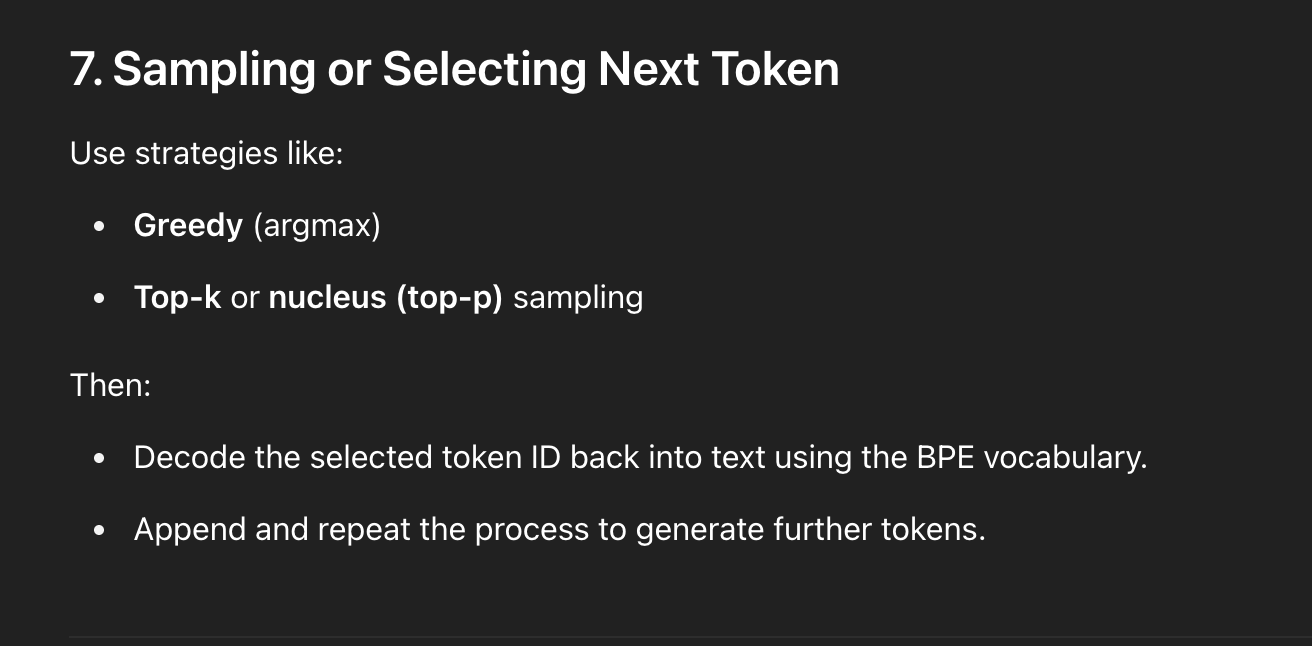
7. Token Selection
Top token is chosen via greedy or sampled method:
- Greedy: pick highest probability
- Top-k/Top-p: sample from most likely tokens
This token is decoded and fed back to generate the next.
✅ Summary
| Step | Description |
|---|---|
| 1 | BPE Tokenization |
| 2 | Token → Embedding |
| 3 | Add Position Encoding |
| 4 | Transformer Layers |
| 5 | Contextual Embeddings |
| 6 | Output Logits & Softmax |
| 7 | Choose Next Token |
🧠 GPT-2 Processing Pipeline Simpler Explanation
How a GPT-like LLM Processes a Sentence: A Step-by-Step Example
This document explains the journey of a simple sentence through the core stages of a Generative Pre-trained Transformer (GPT) like Large Language Model.
Sample Sentence: The cat sat on the mat.
Stage 1: Tokenization
The model first breaks the input text into "tokens" or "subwords" using a tokenizer like Byte-Pair Encoding (BPE). This allows it to handle any word by breaking it down into known pieces from its vocabulary.
| Original Word | Token(s) |
|---|---|
The |
The |
cat |
cat |
sat |
sat |
on |
on |
the |
the |
mat |
mat |
. |
. |
For this simple sentence, each word is a single token. A more complex word like "tokenization" might be split into token and ization.
Output of this stage: A sequence of subword tokens: ["The", "cat", "sat", "on", "the", "mat", "."]
Stage 2: Convert to Token IDs
Next, the model converts each token into a unique integer ID by looking it up in its vocabulary. Every token has a corresponding ID.
(Note: These are example IDs for illustration purposes only. The actual IDs would depend on the specific model's vocabulary.)
| Token | Example Token ID |
|---|---|
The |
464 |
cat |
3797 |
sat |
4354 |
on |
319 |
the |
262 |
mat |
8699 |
. |
13 |
Output of this stage: A sequence of integers: [464, 3797, 4354, 319, 262, 8699, 13]
Stage 3: Embedding
The model converts each Token ID into a high-dimensional vector called an "embedding." This is done using a learned Embedding Matrix. Each vector represents the token's semantic meaning. For this example, let's assume a simplified embedding dimension of 4 (in reality, it's often 1536 or more).
| Token ID | Embedding Vector (Simplified Example) |
|---|---|
464 |
[0.1, -0.4, 0.8, 0.2] |
3797 |
[0.9, 0.2, -0.1, 0.5] |
4354 |
[-0.3, 0.6, 0.4, -0.7] |
319 |
[0.5, -0.5, 0.1, 0.3] |
262 |
[0.1, -0.4, 0.8, 0.2] |
8699 |
[0.7, 0.1, -0.2, 0.4] |
13 |
[-0.9, -0.8, -0.5, -0.1] |
Output of this stage: A sequence of vectors (a matrix).
Stage 4: Positional Encoding
The model adds Positional Encoding vectors to the embedding vectors. This is crucial because the Transformer architecture processes all tokens at once and has no inherent sense of order. This step injects information about the position of each token in the sequence.
| Token | Embedding Vector | + | Positional Vector | = | Final Input Vector |
|---|---|---|---|---|---|
The |
[0.1, -0.4, ...] |
+ | [0.0, 1.0, ...] |
= | [0.1, 0.6, ...] |
cat |
[0.9, 0.2, ...] |
+ | [0.8, 0.5, ...] |
= | [1.7, 0.7, ...] |
sat |
[-0.3, 0.6, ...] |
+ | [0.9, -0.4, ...] |
= | [0.6, 0.2, ...] |
... |
... |
+ | ... |
= | ... |
Output of this stage: A sequence of vectors where each vector contains both semantic and positional information.
Stage 5: Multi-Head Self-Attention
This is the core of the model. The sequence of vectors is processed through multiple layers of Self-Attention. In each layer, for every token, the model calculates how relevant all other tokens are to it. This allows the model to build a deep, contextual understanding.
For example, when processing the word sat, the attention mechanism would learn that cat is the subject and on the mat describes where the action took place. The vector for sat is updated with this contextual information from the other vectors.
This process happens in parallel across multiple "attention heads," each learning different types of relationships within the text.
Output of this stage: A sequence of highly context-aware vectors. The vector for each token is now enriched with information from the entire sentence.
Stage 6: Prediction (Generating the Next Token)
To predict what comes after the final token (.), the model performs the following steps:
Select the Final Vector: It takes the final, context-rich vector corresponding to the last token (
.). This vector contains the distilled meaning and context of the entire sentence that came before it.Projection to Logits: This final vector is passed through a linear layer that projects it into a very large vector called the logits vector. This vector has a size equal to the entire vocabulary (e.g., 50,257 dimensions). Each element in this vector is a raw score for a potential next token.
Final Vector for "." -> [Linear Layer] -> Logits Vector (size 50,257)[..., -1.2, 3.4, 0.1, 5.6, ...]Softmax for Probabilities: The logits vector is passed through a Softmax function, which converts the raw scores into a probability distribution. Each score becomes a probability between 0 and 1, and all probabilities sum to 1.
Logits Vector -> [Softmax] -> Probability Distribution[..., 0.001, 0.08, 0.003, 0.65, ...]Sampling: The model now has a probability for every word in its vocabulary. Instead of always picking the word with the highest probability, it uses a sampling technique (like Top-k or Nucleus sampling) to choose the next token. This introduces creativity and and prevents repetitive responses.
Let's say the token with the highest probability is The (ID 464), and another with high probability is A (ID 314). The model might choose either one based on the sampling strategy.
Final Output: A single predicted token ID, which is then converted back to a word and appended to the sequence. The entire process then repeats to generate the next word.