
Here's a 4-week, visual-first learning plan to master Transformer architecture, LLMs, and GPTs, tailored for visual learners.
|
|
Activation Functions - EXPLAINED! |
|
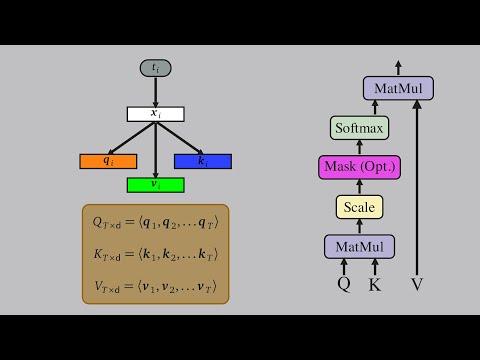
Self-Attention Using Scaled Dot-Product Approach |

|
Multi-Head Attention Visually Explained |
|
|
Self-Attention Using Scaled Dot-Product Approach |

|
Feed forward neural networks |
|
Attention in transformers, step-by-step | DL6 |

|
Transformers in Deep Learning | Introduction to Transformers |

|
Coding Transformer From Scratch With Pytorch in Hindi Urdu || Training | Inference || Explanation |

|
Multi-headed attention |

|
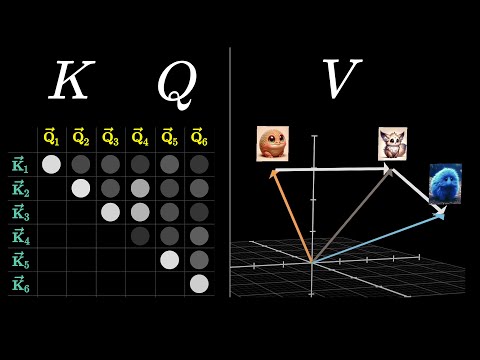
The math behind Attention: Keys, Queries, and Values matrices |

|
EASIEST Way to Train LLM Train w/ unsloth (2x faster with 70% less GPU memory required) |
|
|
Attention in transformers, step-by-step | DL6 |

|
From Attention to Generative Language Models - One line of code at a time! |

|
Finetune LLMs to teach them ANYTHING with Huggingface and Pytorch | Step-by-step tutorial |

|
Building LLMs from the Ground Up: A 3-hour Coding Workshop |

|
Lecture 1: Building LLMs from scratch: Series introduction |
https://sebastianraschka.com/pdf/slides/2024-build-llms.pdf
| Day | Topic | Resource | Activity |
|---|---|---|---|
| 1 | Basics of Neural Networks | 3Blue1Brown: Neural Networks Playlist | Watch first 3 videos |
| 2 | Embeddings & Vectors | Visualizing Word Embeddings + Blog | Play with TensorFlow Projector |
| 3 | Introduction to Attention | Jay Alammar: Attention is All You Need | Read slowly with notes |
| 4 | Animated Attention Demo | YouTube: The Transformer Explained Visually | Watch and take notes |
| 5 | Quiz and Drawing Day | Self-made quiz using Notion or paper | Redraw attention flow diagram |
| 6 | Use Attention Visualization Tool | Harvard NLP Annotated Transformer | Play and understand how layers work |
| 7 | Recap and Reflect | Journal-style reflection | Draw how attention enables learning context |
| Day | Topic | Resource | Activity |
|---|---|---|---|
| 1 | Transformer Block Overview | Karpathy: GPT from Scratch Video (1st 30 min) | Pause often and sketch |
| 2 | Positional Encoding | The Illustrated Transformer (second half) | Use sine/cosine animation |
| 3 | Self-Attention Visualized | BERTViz or video explanation | Explore how heads attend |
| 4 | Feed-Forward Networks | Hugging Face Course + Visualizer Notebook | Understand FFN layers visually |
| 5 | Layer Normalization & Residuals | Watch short clip or draw layer flow | Note down effects on gradients |
| 6 | Build a visual Transformer diagram | Use Miro, Excalidraw or Canva | Label each component |
| 7 | Recap with a mini explainer | Record a 3-min explanation video | Share with a friend or online |
| Day | Topic | Resource | Activity |
|---|---|---|---|
| 1 | GPT vs BERT Overview | Visual Blog | Diagram causal vs bidirectional |
| 2 | Tokenization & Byte Pair Encoding | Hugging Face Tokenizer Visualizer | Try BERT vs GPT tokenizer |
| 3 | GPT Architecture | Karpathy minGPT GitHub | Look at model.py visually |
| 4 | Attention Heads Behavior | TransformerLens Tool | Explore and record findings |
| 5 | Embedding Visuals | Use t-SNE or PCA to visualize token embeddings | Optional: Try on Colab |
| 6 | Compare BERT, GPT2, GPT3 | Table and diagram creation | Use arrows to mark key changes |
| 7 | Recap + “Teach-back” Day | Explain GPT to an imaginary 12-year-old | Visual flowchart aid |
| Day | Topic | Resource | Activity |
|---|---|---|---|
| 1 | Explore LMSYS Chatbot Arena | https://chat.lmsys.org/ | Compare LLMs in action |
| 2 | Streamlit LLM Playground | Use basic UI to explore outputs | Add sliders to modify prompts |
| 3 | Visualize Attention in a Colab | Use BERTviz or custom notebook | Show attention weights per layer |
| 4 | Build Tiny GPT | Follow nanoGPT or Simple GPT | Watch model in training |
| 5 | Create Visual Slide Deck | PowerPoint, Canva, or Notion | Each slide explains a block |
| 6 | Share Your Visual Guide | Blog, Medium, or YouTube | Title: “How I learned Transformers visually” |
| 7 | Celebration & Reflection | Reflect on growth, challenges, and goals | Plan next phase: finetuning or prompt engineering |
Would you like me to package this plan as a downloadable PDF or Notion template with all links embedded?
For a visual learner, the best way to learn Transformer architecture, LLMs, and GPTs is through structured, visual-first resources that blend intuition with animations, diagrams, and interactive tools. Here's a curated path:
Animated Videos:
Jay Alammar's YouTube and blog:
Papers with Code – Visualizations:
Harvard NLP’s Visual Transformer Demo:
LMSYS Playground (ChatBot Arena):
TransformerLens:
Google Colab notebooks with visualization:
FastAI's NLP Course (has visuals and animations):
Andrej Karpathy’s Lectures (YouTube):
Let's walk step-by-step through self-attention and multi-head attention using a sentence of 6 tokens, an embedding size of 512, and 8 attention heads. This will involve:
Let’s take this simple 6-token sentence:
"The cat sat on the mat"We'll call this S = [t₁, t₂, t₃, t₄, t₅, t₆], where each tᵢ is a token.
Each token is converted to a 512-dimensional vector via a learned embedding table.
S = (6,)E = (6, 512) — 6 tokens, each with 512 featuresExample:
t₁ = "The" → [0.12, 0.88, ..., 0.55] (512-dim vector)
...same for other tokens.
Since self-attention has no sense of sequence, we add positional encoding.
(6, 512)Each position pos and dimension i is computed as:
PE(pos, 2i) = sin(pos / 10000^(2i/512))
PE(pos, 2i+1) = cos(pos / 10000^(2i/512))Add this to the embedding:
X = E + PE → shape = (6, 512)For each token, we compute:
We have weight matrices for each:
Wq, Wk, Wv ∈ ℝ⁵¹²ˣ⁶⁴ (because 512 / 8 = 64 per head)So for each head:
Q = X @ Wq → shape (6, 64)
K = X @ Wk → shape (6, 64)
V = X @ Wv → shape (6, 64)For each token i, compute attention to every token j:
score(i, j) = (Q[i] · K[j]) / √64This gives a score matrix of shape (6, 6)
(Each token attends to every other token including itself.)
Apply softmax across each row → normalize attention weights.
Then multiply weights with V:
Attention[i] = softmax(score[i]) @ V
→ shape = (6, 64)Do steps 3–4 for all 8 heads in parallel:
(6, 64) output(6, 8×64) = (6, 512)Then apply a final linear projection:
Output = (6, 512) @ Wₒ (where Wₒ ∈ ℝ⁵¹²ˣ⁵¹²)The output (6, 512) is passed through:
We only take the final token's output vector:
x₆ = Output[5] → (512,)Project it to vocab size (e.g., 50,000):
logits = x₆ @ W_vocab.T → (50,000,)
next_word = softmax(logits)| Step | Shape |
|---|---|
| Token Embedding | (6, 512) |
| + Positional Encoding | (6, 512) |
| Q, K, V per head | (6, 64) |
| Attention Weights | (6, 6) |
| Output per head | (6, 64) |
| Concatenated Heads | (6, 512) |
| Final Output | (6, 512) |
| Next Token Logits | (50,000,) |
Would you like me to visualize these with matrices and real numbers or build a small Python simulation of this with dummy data?
You just ran a simplified single-head self-attention mechanism in Python using a 6-token sequence, each with a 512-dim embedding split into 64-dim heads.
Would you like:
Let me know how deep you want to go!
Here’s what you’ve just accomplished through this multi-head attention pipeline:
Sentence Representation Simulated a 6-token sentence with 512-dim learned embeddings.
Positional Encoding Added sinusoidal positional vectors to give the model sequence awareness.
Q, K, V Projections (8 heads) Projected each token into 8 different Query, Key, Value spaces using learned weights:
(6, 64) per headSelf-Attention (Head-wise)
V and collected attention outputs.Concatenation & Linear Projection
(6, 512)Feedforward Neural Network
ReLU) → (6, 512)Vocabulary Projection & Softmax
You saw a heatmap of attention weights for Head 0, showing how each token attends to others.
The top 5 "predicted" tokens (just dummy token indices here):
Token indices: [3273, 9999, 3330, 3337, 3336]
Probabilities: [1. 0. 0. 0. 0.]The top prediction is token 3273, since we only used random weights — the real model would train these over time using backpropagation and loss.
Would you like:
Let me know!
Great! Let’s build an interactive self-attention visualizer using real words and embeddings with 🤗 Hugging Face Transformers and torch.
You’ll:
bert-base-uncased!pip install transformers torch matplotlib seaborn --quietimport torch
from transformers import BertTokenizer, BertModel
import seaborn as sns
import matplotlib.pyplot as plt
# Load BERT base model and tokenizer
model_name = 'bert-base-uncased'
tokenizer = BertTokenizer.from_pretrained(model_name)
model = BertModel.from_pretrained(model_name, output_attentions=True)
model.eval()sentence = "The cat sat on the mat"
inputs = tokenizer(sentence, return_tensors='pt')
with torch.no_grad():
outputs = model(**inputs)
# Get attention from all layers and heads
attentions = outputs.attentions # Tuple of 12 layers, each (1, 12, seq_len, seq_len)
tokens = tokenizer.convert_ids_to_tokens(inputs['input_ids'][0])# Choose layer and head
layer_num = 0 # 0 to 11
head_num = 0 # 0 to 11
attn = attentions[layer_num][0, head_num] # (seq_len, seq_len)
# Plot
plt.figure(figsize=(8, 6))
sns.heatmap(attn, xticklabels=tokens, yticklabels=tokens, cmap="Blues", annot=True, fmt=".2f")
plt.title(f"Layer {layer_num + 1} Head {head_num + 1} Attention")
plt.xlabel("Key")
plt.ylabel("Query")
plt.show()layer_num and head_num to explore other heads/layersWould you like this wrapped into a Streamlit app or Gradio UI to allow sliders/dropdowns for real-time interaction?
Or exported as a Colab notebook link or PPT/PDF visual explanation of what you just explored?
Here’s an approachable walkthrough of “Attention Is All You Need” (Vaswani et al., 2017), the paper that introduced the Transformer—and how its ideas evolved into GPT-2 and other modern models.
Given queries Q, keys K, and values V (all matrices):
Attention(Q,K,V) = softmax( QKT / √dₖ ) · VInstead of one attention, use h separate “heads”:
Why multi-head?
Since attention alone is order-agnostic, the paper adds sinusoidal positional encodings to the input embeddings:
PE(pos,2i) = sin(pos / 10000^(2i/d_model))
PE(pos,2i+1) = cos(pos / 10000^(2i/d_model))Each encoder/decoder layer includes a small fully-connected network applied to each position separately:
FFN(x) = max(0, xW₁ + b₁)W₂ + b₂Encoder: A stack of N identical layers, each with
Decoder: Also N layers, but each layer has
Each sub-layer has a residual connection + layer normalization:
LayerNorm(x + SubLayer(x))This stabilizes training and helps gradient flow.
Because every layer is fully parallelizable (no recurrence), training is much faster on GPUs/TPUs.
GPT-2 (Radford et al., 2019) builds directly on the Transformer decoder:
| Aspect | Original Transformer | GPT-2 |
|---|---|---|
| Architecture | Encoder–decoder stack | Decoder-only stack |
| Attention | Bidirectional in encoder; masked in decoder | Always causal (masked) self-attention |
| Position encodings | Sinusoidal | Learned embeddings |
| Objective | Seq2seq (translation) | Unidirectional language modeling (predict next token) |
| Layer Norm Placement | Post-sub-layer | Pre-sub-layer (“pre-norm”), which can ease training in very deep stacks |
| Depth & Width | 6 layers, d_model=512, 8 heads | Up to 48 layers, d_model=1600 (varies by variant), 25+ heads |
In sum, “Attention Is All You Need” replaced RNNs/CNNs with a fully parallel, attention-centric architecture. GPT-2 is a direct descendant that prunes away the encoder, uses causal masking for text generation, and scales up massively in size—and the same core ideas power most state-of-the-art NLP models today.
When you read “project into lower-dimensional subspaces,” it doesn’t contradict the fact that in code you often see a single 768→2304 linear layer for QKV. Here’s what’s really happening:
Model vs. head dimension
Combined QKV projection (768 → 2304)
For efficiency, frameworks pack the three projections into one matrix:
$$ W{\text{inproj}} \in \mathbb{R}^{d{!model}\times 3d{!model}} \quad:\quad X\,W{\text{inproj}} ~\in~ \mathbb{R}^{\text{seq}\times 3d_{!model}} $$
Numerically, 768×2304 = three copies of 768, one each for Q, K and V.
Splitting into Q, K, V
You slice that 2304-dim vector into three 768-dim chunks:
$$ [Q{\text{flat}},\,K{\text{flat}},\,V_{\text{flat}}] ~\in~ \mathbb{R}^{\text{seq}\times 768}\;\times3 $$
Reshaping into h heads (lower-dimensional!)
Each 768-dim vector is then reshaped to (h, d_k):
$$ 768 \;\longrightarrow\; (12 \times 64) \quad\text{so each head has dimension } d_k=64. $$
Now your queries, keys, and values live in twelve 64-dim subspaces, each much smaller than 768.
Constant compute: If you did 12 heads each of size 768, you’d multiply your FLOPs by 12. By making each head size 64, the total cost stays
$$ h \times (\text{seq}^2 \times dk) = \text{seq}^2 \times (h\cdot dk) = \text{seq}^2 \times d_{!model}. $$
Specialization: Different heads can focus on different kinds of relationships (syntax vs. semantics, local vs. global patterns), improving representational power without extra cost.
Stable optimization: Lower-dim dot products (64‐dimensional) have smaller variance than huge 768-dim ones, which helps training.
In short:
Under the hood, the step that takes your 768-dimensional token embedding x and turns it into the concatenated Q, K, V vector is simply a single linear transformation:
Combined projection weight You have a learned weight matrix
$$ W{\text{inproj}}\;\in\;\mathbb R^{\,d{!model}\,\times\,3\,d_{!model}} \;=\;\mathbb R^{768\times(3\times768)} \;=\;\mathbb R^{768\times2304} $$
and a bias vector
$$ b_{\text{inproj}}\;\in\;\mathbb R^{2304}. $$
Linear map When you apply it to your embedding
$$ x\in\mathbb R^{768}, $$
you compute
$$ \bigl[xW{\text{inproj}} + b{\text{inproj}}\bigr]\;\in\;\mathbb R^{2304}. $$
That 2304-dim vector is literally $[Q{\mathrm{flat}}\;|\;K{\mathrm{flat}}\;|\;V_{\mathrm{flat}}]$, three 768-dim slices stuck end to end.
Why 2304 (not 2308)? The standard Transformer always uses exactly $3\times d_{!model}$. If you saw “2308” it’s either a typo or comes from a custom variant that padded or added extra parameters—but the vanilla Vaswani et al. model is $3\times768=2304$.
Splitting into Q, K, V In code you’ll see something like (PyTorch-style):
# in_proj_out: [batch, seq_len, 2304]
in_proj_out = linear(x, W_inproj, b_inproj)
# now split into three 768-dim tensors
Q_flat, K_flat, V_flat = in_proj_out.chunk(3, dim=-1)Reshaping for multi-head Each of those 768-dim vectors is then reshaped into your h heads of size dₖ = 768/ h (e.g. 12 heads of 64 dims):
# from [batch, seq_len, 768] → [batch, h, seq_len, d_k]
Q = Q_flat.view(batch, seq_len, h, d_k).transpose(1,2)
# same for K and VIn summary: