Welcome to your own hands-on guide to training, fine-tuning, converting, and running your own Tiny Language Model (LLM)! 🎓🚀
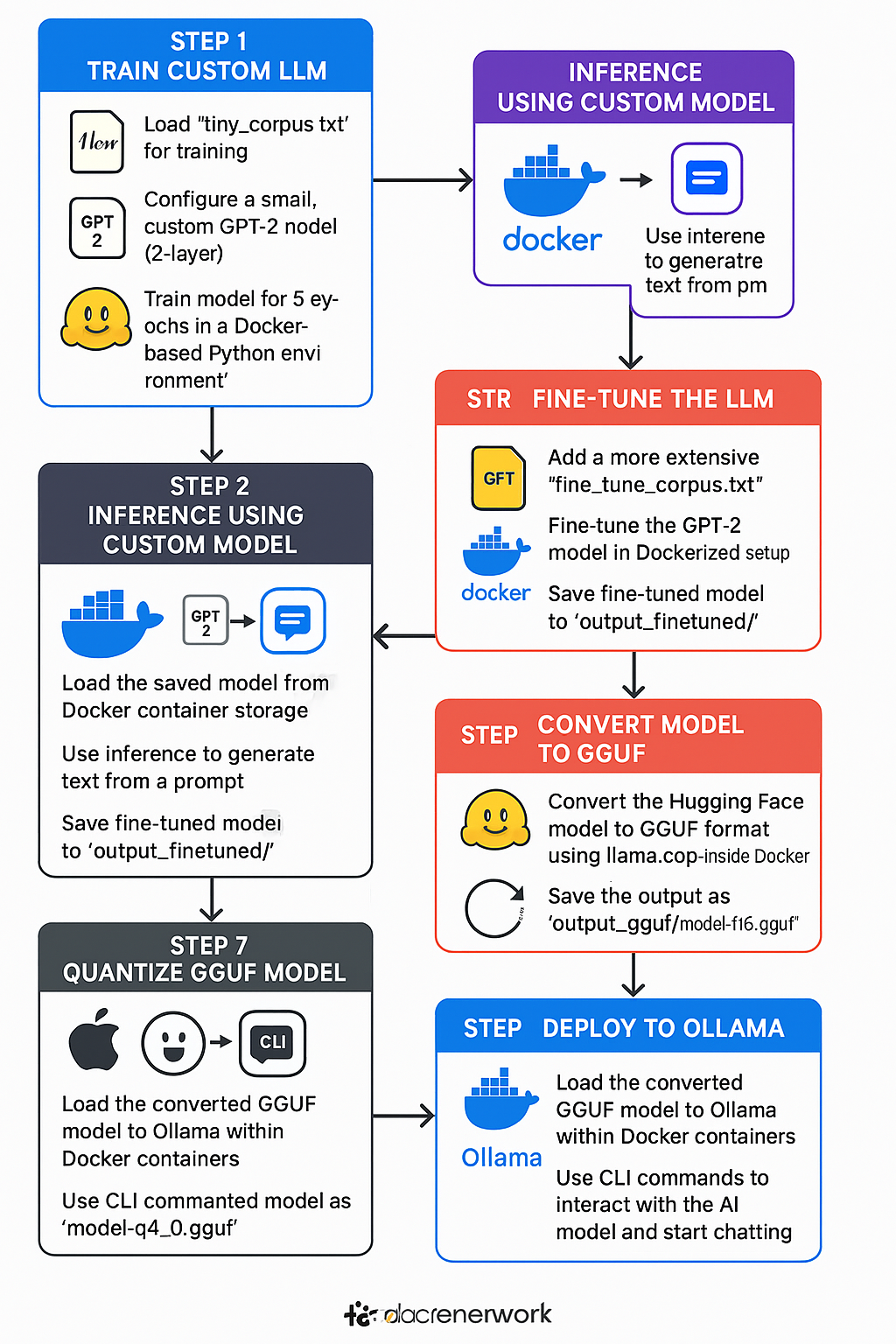
This tutorial is built in 8 exciting steps that use Docker containers to make it easy for anyone (even a teen!) to experiment with machine learning. Each step is a folder with Docker instructions to automate it. Here’s what each step does and how to understand it.
output_model/.
Epoch 1/5, Loss: 10.8263
Epoch 5/5, Loss: 9.0925
Absolutely! Here's a textual flowchart/tree of what happens in step1_train_custom/train.py, with explanations of each stage:
🧠 START: train.py
│
├── 📂 Load & Preprocess Data
│ ├── Open 'data/tiny_corpus.txt'
│ ├── Read full text into memory
│ └── Use GPT-2 tokenizer:
│ ├── Load pre-trained tokenizer ("gpt2")
│ ├── Set padding to left
│ └── Use EOS token as pad token
│
├── 🔢 Tokenize Text
│ └── Convert raw text → token IDs using tokenizer
│ └── Store as `input_ids` (PyTorch tensor)
│
├── 🏗️ Define Tiny Model Architecture
│ └── Start from GPT-2 config and override:
│ ├── n_layer = 2 (2 transformer decoder blocks)
│ ├── n_head = 2 (2 attention heads)
│ ├── n_embd = 128 (embedding size)
│ └── vocab_size = from tokenizer
│
├── 🧠 Create Model from Config
│ └── `AutoModelForCausalLM.from_config(config)`
│
├── ⚡ Set Device
│ └── If Apple M1/M2 chip → use "mps", else use "cpu"
│
├── 🛠️ Training Loop (5 epochs)
│ ├── Set optimizer: AdamW with learning rate 5e-4
│ ├── For each epoch:
│ │ ├── Clear gradients
│ │ ├── Forward pass: model(input_ids)
│ │ ├── Compute loss (Causal LM loss)
│ │ ├── Backward pass: loss.backward()
│ │ └── Optimizer step
│ └── Print training loss
│
├── 💾 Save Model & Tokenizer
│ ├── Create "output_model" directory
│ ├── Save model weights & config
│ └── Save tokenizer vocab & config
│
└── ✅ Done: Print confirmation messageGlad you liked the first one! Here's the textual flowchart/tree for step2_inference_custom/generate.py – explained for clarity and ease of understanding:
🧠 START: generate.py
│
├── 📦 Load Model & Tokenizer
│ ├── Define model path: "/app/model" (Docker volume)
│ ├── Load tokenizer from that path
│ └── Load model from that path using Hugging Face
│ └── Set model to evaluation mode (`model.eval()`)
│
├── ⚡ Set Device
│ └── If on Apple M1/M2 → use "mps", else "cpu"
│
├── 📤 Move Model to Device
│ └── Ensures model computations run on correct hardware
│
├── ✍️ Define Prompt
│ └── User-defined starting text: "Hello, how"
│
├── 🔢 Tokenize Prompt
│ └── Convert prompt → token IDs using tokenizer
│ └── Move tokenized input to device
│
├── 🤖 Generate Text
│ ├── Turn off gradient tracking (faster, less memory)
│ ├── Run `model.generate()`:
│ │ └── Generate up to 10 new tokens
│ └── Decode output token IDs into human-readable text
│
└── 🖨️ Print Result
└── Display both the prompt and the model's continuationno_grad() (means “don’t learn, just think!”).fine_tune_corpus.txt).output_finetuned/.🧠 START: finetune.py
│
├── 📖 Load Fine-tune Text
│ └── Read from: data/fine_tune_corpus.txt
│ └── Example lines like:
│ "I am a tiny model."
│ "Let's see what I can learn."
│
├── ✏️ Tokenize Fine-tune Data
│ ├── Load GPT-2 tokenizer from Hugging Face
│ ├── Set padding to the left (helps align input)
│ ├── Set pad token to be same as end-of-sentence token
│ └── Convert input text into token IDs (tensors)
│
├── 🛠️ Load Model from Disk
│ └── Load previously trained model from ../step1 output
│ └── Move model to Apple MPS or CPU
│ └── Set model to train mode
│
├── ⚙️ Prepare Optimizer
│ └── Use AdamW optimizer (designed for transformers)
│ └── Learning rate = 5e-4
│
├── 🔁 Fine-Tuning Loop (Repeat 3 Times)
│ ├── For each epoch:
│ │ ├── Reset gradients
│ │ ├── Run model with input_ids as both input and label
│ │ │ └── Model learns to predict the next word!
│ │ ├── Calculate loss
│ │ ├── Backpropagate (learn!)
│ │ └── Optimizer updates weights
│ └── Print loss for each epoch
│
├── 💾 Save Fine-Tuned Model
│ └── Save model and tokenizer into output_finetuned/ folder
│
└── ✅ Done!
└── Model now knows a little more than before!Here’s the flowchart-style breakdown for step3_finetune_custom/finetune.py, written clearly for a teenager to understand:
Absolutely! Here’s the flowchart-style breakdown of step4_inference_finetuned/generate_finetuned.py, designed for clarity and simplicity (teenager-friendly):
🧠 START: generate_finetuned.py
│
├── 📦 Load Fine-Tuned Model
│ ├── Load tokenizer from /app/model (mapped to fine-tuned folder)
│ ├── Load model (trained on new data in step 3)
│ └── Set model to "eval" mode (inference mode)
│
├── 🧠 Select Device
│ └── Use Apple MPS if available (faster on Mac)
│ else use CPU
│
├── 💬 Create Prompt
│ └── Example: "I am a tiny model"
│
├── ✏️ Tokenize Prompt
│ └── Convert the prompt to token IDs (tensors)
│ └── Move it to the selected device
│
├── 🔮 Generate Response
│ └── Disable gradient tracking (saves memory, speeds up)
│ └── Use `model.generate()` to get predicted continuation
│ └── Limit to max 10 new tokens
│
├── 🧾 Decode Tokens
│ └── Turn generated tokens into readable text
│
└── 📢 Print the Result
├── Show the original prompt
└── Show the model's continuation
✅ ENDWould you like the Step 5 (GGUF conversion) breakdown next?
llama.cpp for faster loading and simpler structure..gguf file using convert_hf_to_gguf.pymodel-f16.ggufGreat! Here’s the flowchart-style breakdown of step5_convert_gguf/convert_to_gguf.py, written clearly for a teenager or beginner to understand what happens during the GGUF conversion step:
🧠 START: convert_to_gguf.py
│
├── 📁 Define Model Paths
│ ├── Input: /app/ft_model (your fine-tuned model from step 3)
│ └── Output: output_gguf/model-f16.gguf (converted GGUF model)
│
├── 🔍 Check & Clone llama.cpp (only if not already present)
│ ├── If llama.cpp folder doesn't exist:
│ │ └── Clone llama.cpp from GitHub (only once)
│ └── Else: skip cloning (already available)
│
├── 📦 Install Required Python Packages
│ ├── transformers – handles Hugging Face models
│ ├── safetensors – reads model weight files safely
│
├── 🔄 Run Conversion Script
│ ├── Use convert_hf_to_gguf.py from llama.cpp
│ ├── Provide input model path and output GGUF file path
│ └── This script:
│ ├── Loads the PyTorch-based model
│ ├── Reads config, tokenizer, weights
│ ├── Transforms it into GGUF format
│ └── Writes it to disk as model-f16.gguf
│
└── ✅ Print Completion Message
└── "GGUF conversion complete"
🏁 ENDllama.cpp, Ollama, or others..gguf file ready for speed!model-q4_0.gguf (a lighter version of your model)Perfect! Here's the flowchart-style breakdown for step6_quantize_gguf/quantize.sh, explaining quantization in simple, beginner-friendly language.
🧠 START: quantize.sh
│
├── 🗂️ Check if GGUF model exists
│ └── model-f16.gguf from Step 5 is expected
│
├── 🔧 Clone llama.cpp (if not already cloned)
│ ├── Used to run quantization tools
│ └── Contains `llama-quantize` tool we need
│
├── 🧱 Build llama.cpp (C++ project)
│ └── Uses CMake to compile binaries inside Docker
│
├── 📉 Run Quantization Command
│ ├── Input: model-f16.gguf (full-precision)
│ ├── Output: model-q4_0.gguf (quantized)
│ ├── Tool: ./build/bin/llama-quantize
│ │
│ └── Quantization Type:
│ └── q4_0 = 4-bit fixed point compression
│ └── Reduces model size ~2x-4x
│
├── 🧪 Print Metadata Summary
│ └── Shows each tensor’s compression details
│
└── ✅ Print Success Message
└── "Quantization complete: model-q4_0.gguf"
🏁 END
>>> hello
Hello there! I’m here to assist you.
Awesome! Here’s the flowchart-style breakdown for step7_ollama_deploy, explaining how the quantized model is packaged and launched using Ollama, in a way that even a curious teenager can grasp:
🚀 START: do.sh (or your custom Ollama script)
│
├── 🧠 Prerequisite: model-q4_0.gguf
│ └── This is your quantized model from Step 6
│
├── 📂 Copy GGUF model to Ollama build folder
│ └── Put model-q4_0.gguf next to Modelfile
│
├── 📜 Modelfile (like a recipe for Ollama)
│ ├── FROM llama3 (or base model)
│ ├── PARAMETERS (e.g., temperature, top_k)
│ └── SYSTEM (optional instructions or role)
│
├── 🏗️ ollama create custom-model -f Modelfile
│ └── This **packages your model** using Ollama’s builder
│ └── Creates a local model named `custom-model`
│
├── 🔄 ollama run custom-model
│ ├── Starts the model like a chatbot
│ ├── Waits for user input (e.g., "hello")
│ └── Responds using your trained brain!
│
└── ✅ Output:
├── Model answers intelligently
├── ollama ps shows running container
└── ollama ls shows all your saved models
🏁 END.gguf model act like ChatGPT — right on your computer!Ready for the grand finale with Step 8: Convert to MLX for Apple Silicon inference?
mlx_lm.convertPerfect! Here's the flowchart-style breakdown for step8_convert_mlx, where you convert your model into MLX format — optimized to run natively and lightning-fast on your Apple Silicon (M1/M2/M3) chip 💻⚡.
🚀 START: sh do.sh (or manual script execution)
│
├── 1️⃣ 🛠️ Create Python Virtual Environment (optional but good)
│ └── python -m venv mlx_env
│ └── source mlx_env/bin/activate
│
├── 2️⃣ 📦 Install dependencies
│ └── pip install mlx-lm
│ ├── Installs Apple's MLX + LLM helpers
│ └── Also pulls: numpy, transformers, sentencepiece, etc.
│
├── 3️⃣ 🔐 Login to Hugging Face CLI (if fetching public models)
│ └── huggingface-cli login
│
├── 4️⃣ 🧠 Prepare model directory
│ └── Make sure `output_model/` from Step 5 has:
│ ├── config.json
│ ├── tokenizer.json / vocab
│ └── model.safetensors
│
├── 5️⃣ 📁 Convert using mlx-lm
│ └── Command:
│ mlx_lm convert output_model/ mlx_models/custom-mlx-model
│ ├── Loads Hugging Face format
│ ├── Converts to `.mlx` tensors + tokenizer
│ └── Saved under `mlx_models/` folder
│
├── 6️⃣ ✅ Check Output
│ └── Directory will have:
│ ├── model.mlxtensors
│ ├── tokenizer.model
│ └── config.json
│
├── 7️⃣ 🧪 Run locally
│ ├── mlx-lm chat --model mlx_models/custom-mlx-model
│ └── Now you can chat with your trained model fully on-device
│
└── 🧠 Output:
├── Prompt: Hello, how are you?
└── Reply: I am a tiny custom model running natively on your Mac 💡
🏁 ENDMLX (Machine Learning eXecution) is Apple’s custom framework that: - Uses GPU & Neural Engine in M1/M2/M3 chips - Runs models 2x–5x faster than PyTorch on Mac - Is great for low-latency, battery-friendly AI apps
| Feature | Value |
|---|---|
| 🔥 Speed | Runs directly on Mac GPU |
| ⚡ Efficiency | No Docker needed |
| 🎯 Simplicity | Just run mlx-lm chat |
| 🧠 Personal | Your own trained model |
Let me know if you'd like me to: - ✅ Generate an infographic or diagram version - ✅ Help run this model in a Streamlit or web UI - ✅ Explain how to upload MLX models to Hugging Face - ✅ Bundle all 8 steps into a markdown eBook or GitHub README
Would you like that?
This tutorial turns you into a creator — not just a user — of LLMs. 🧠💬
Well done, AI engineer! 🚀
In this tutorial, we'll build a complete end-to-end pipeline for training and deploying a tiny Transformer-based language model on Apple Silicon (Mac M1/M2). We will go through all stages: from training a custom model on a small dataset, saving it in Hugging Face format, performing inference and fine-tuning, and then converting and deploying the model in optimized formats (GGUF for llama.cpp/Ollama and MLX for Apple Metal acceleration). Each stage is containerized with Docker for reproducibility, and we’ll ensure compatibility with Mac M1/M2 GPUs via Apple’s Metal Performance Shaders (MPS) and the Apple MLX framework when appropriate. We will demonstrate two use cases: a tiny custom Transformer model we train from scratch, and the open-source TinyLLaMA (1.1B parameters) model (TinyLlama: An Open-Source Small Language Model - arXiv) for LLaMA-like deployment.
Tools & Frameworks Used: Hugging Face Transformers and PyTorch (for training/fine-tuning on MPS (Accelerated PyTorch training on Mac - Metal - Apple Developer)), transformers pipelines (for inference), llama.cpp (for GGUF conversion & quantization (Quantizing Large Language Models: A step by step example with Meta-Llama-3.1–8B-Instruct Model | by Necati Demir | Medium)), Ollama (to serve GGUF models), and mlx-lm (to convert and run models with Apple’s MLX framework (mlx-community/Llama-3.2-3B-Instruct-4bit · Hugging Face) (MLX-LM - Qwen)). All stages are organized into separate Docker environments, each with its own Dockerfile and docker-compose.yml.
We'll organize the project into folders for each step. This modular approach makes it clear and allows using Docker Compose to manage each stage’s environment. A possible directory structure is:
llm-pipeline/
├── step1_train_custom/ # Train custom tiny Transformer
│ ├── Dockerfile
│ ├── docker-compose.yml
│ ├── data/
│ │ └── tiny_corpus.txt
│ └── train.py
├── step2_inference_custom/ # Inference with the custom model
│ ├── Dockerfile
│ ├── docker-compose.yml
│ └── generate.py
├── step3_finetune_custom/ # Fine-tune the custom model on new data
│ ├── Dockerfile
│ ├── docker-compose.yml
│ ├── data/
│ │ └── fine_tune_corpus.txt
│ └── finetune.py
├── step4_inference_finetuned/ # Inference with fine-tuned model
│ ├── Dockerfile
│ ├── docker-compose.yml
│ └── generate_finetuned.py
├── step5_convert_gguf/ # Convert model to GGUF format
│ ├── Dockerfile
│ ├── docker-compose.yml
│ └── convert_to_gguf.py
├── step6_quantize_gguf/ # Quantize the GGUF model (e.g., Q4_0, Q5)
│ ├── Dockerfile
│ ├── docker-compose.yml
│ └── quantize.sh
├── step7_ollama_deploy/ # Import and run model in Ollama
│ ├── Modelfile # Ollama model definition
│ ├── docker-compose.yml
│ └── README.md # Instructions to run Ollama
└── step8_convert_mlx/ # Convert model to MLX format
├── Dockerfile
├── docker-compose.yml
└── convert_to_mlx.pyNote: In practice, steps 1–5 focus on the custom tiny model pipeline, while steps 5–8 demonstrate deployment using a LLaMA-style model (we’ll use TinyLLaMA 1.1B as an example). You can apply steps 5–8 to either the fine-tuned custom model if its architecture is supported by the tools, or more typically to a LLaMA-based model like TinyLLaMA for compatibility.
Each stage’s Docker container will output artifacts (model weights, etc.) to a mounted volume so that subsequent stages can access them without manual copying. Now, let’s go through each step in detail.
Goal: Train a small Transformer-based language model from scratch on a very small text dataset. We will use Hugging Face Transformers with PyTorch. On Mac M1/M2, we can leverage the MPS backend to accelerate training on the Apple GPU (Accelerated PyTorch training on Mac - Metal - Apple Developer). Our custom model will be tiny (few layers and dimensions) for demonstration purposes.
Sample Training Data: Create a toy corpus with just a few sentences. For example, in step1_train_custom/data/tiny_corpus.txt:
Hello, how are you?
I am fine. How about you?
This is a tiny dataset for a tiny transformer.Feel free to include any small, simple text — the model will just memorize patterns from this tiny corpus.
Model Architecture: We'll define a small causal Transformer. To keep things simple, we can use a GPT-2 style architecture with reduced dimensions. Hugging Face provides a GPT2 config that we can customize for a tiny model. For example, set only 2 layers, 2 attention heads, and a small embedding size.
Training Script (train.py): This script will:
AutoModelForCausalLM using a custom config (or you can use GPT2LMHeadModel with a small config).Below is a simplified training script:
# step1_train_custom/train.py
import os
import torch
from transformers import AutoTokenizer, AutoConfig, AutoModelForCausalLM
# 1. Prepare dataset
data_path = "data/tiny_corpus.txt"
with open(data_path, 'r') as f:
text = f.read()
# Simple preprocessing: split into lines and tokenize
tokenizer = AutoTokenizer.from_pretrained("gpt2") # use pre-trained GPT2 tokenizer
tokenizer.padding_side = "left"
tokenizer.pad_token = tokenizer.eos_token # pad token needed for GPT2
# Encode the entire text into tokens (for tiny dataset, we do a simple approach)
inputs = tokenizer(text, return_tensors='pt')
input_ids = inputs["input_ids"]
# 2. Define tiny model config (GPT-2 architecture with reduced size)
config = AutoConfig.from_pretrained("gpt2")
config.n_layer = 2 # 2 transformer decoder layers
config.n_head = 2 # 2 attention heads
config.n_embd = 128 # embedding dimension
config.vocab_size = tokenizer.vocab_size
model = AutoModelForCausalLM.from_config(config)
# Use Apple MPS if available for speed
device = torch.device("mps") if torch.backends.mps.is_available() else torch.device("cpu")
model.to(device)
model.train()
# 3. Training loop (very basic)
optimizer = torch.optim.AdamW(model.parameters(), lr=5e-4)
epochs = 5
for epoch in range(epochs):
# For simplicity, feed the whole corpus as one sequence (tiny dataset)
optimizer.zero_grad()
outputs = model(input_ids.to(device), labels=input_ids.to(device))
loss = outputs.loss
loss.backward()
optimizer.step()
print(f"Epoch {epoch+1}/{epochs}, Loss: {loss.item():.4f}")
# 4. Save model & tokenizer in Hugging Face format
os.makedirs("output_model", exist_ok=True)
model.save_pretrained("output_model")
tokenizer.save_pretrained("output_model")
print("Model saved to output_model/")A few notes on this script:
output_model/. Hugging Face’s save_pretrained() will create a directory with model weights and config (e.g., pytorch_model.bin or model.safetensors, plus config.json, etc.) (Quantizing Large Language Models: A step by step example with Meta-Llama-3.1–8B-Instruct Model | by Necati Demir | Medium).Docker Setup: The Dockerfile for this stage needs a Python environment with PyTorch and Transformers. We will use an ARM64 base image (so it runs natively on M1/M2). For GPU support, note that Apple’s MPS backend requires running on macOS; inside a Linux container we won't have GPU access. So, our container will run on CPU by default, but since the model is small, this is fine (if you want GPU, you could run training directly on macOS or explore experimental approaches to use macOS as a container runtime).
step1traincustom/Dockerfile:
# Use a lightweight base for Python on arm64
FROM python:3.10-slim
# Install necessary packages
RUN pip install torch torchvision torchaudio transformers datasets safetensors
# Copy training script and data
WORKDIR /app
COPY train.py .
COPY data/ ./data/
# Set environment to avoid any interactive prompts
ENV PYTHONUNBUFFERED=1
# Command to run training
CMD ["python", "train.py"]step1traincustom/docker-compose.yml:
version: "3.8"
services:
train_custom:
build: .
platform: linux/arm64 # ensure ARM architecture
volumes:
- ./:/app # mount current directory into container (read-write)
- output_model/:/app/output_model # mount output dir to get saved modelThis Compose file mounts the output directory so that the saved model persists on the host. Run this stage with:
# In llm-pipeline/step1_train_custom
docker-compose up --buildThis will build the container and execute the training. After completion, you should see the saved model files on your host in step1_train_custom/output_model/. For example, you’ll have a config.json, pytorch_model.bin (or model.safetensors), and tokenizer files (vocab.json, merges.txt, etc., for GPT2 tokenizer).
Verification: The model is now in Hugging Face Transformers format. You can inspect output_model/config.json to confirm the architecture (e.g., 2 layers, 2 heads, etc.). This completes the training and saving steps (Steps 1 and 2).
Now that we have a trained model, let's load it and generate text (Step 3). We’ll do this in a separate container to simulate a deployment environment for inference.
Inference Script (generate.py): This will load the model and tokenizer from the saved directory and produce an output given a prompt.
# step2_inference_custom/generate.py
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
# Load the model and tokenizer from the saved directory
model_dir = "/app/model" # this will be a mounted volume
tokenizer = AutoTokenizer.from_pretrained(model_dir)
model = AutoModelForCausalLM.from_pretrained(model_dir)
model.eval()
# Use MPS if available
device = torch.device("mps") if torch.backends.mps.is_available() else torch.device("cpu")
model.to(device)
# Define a prompt for the model
prompt = "Hello, how"
inputs = tokenizer(prompt, return_tensors='pt').to(device)
# Generate continuation
with torch.no_grad():
outputs = model.generate(**inputs, max_new_tokens=10)
generated_text = tokenizer.decode(outputs[0])
print(f"Prompt: {prompt}\nModel continuation: {generated_text}")Since our model was trained on a very limited corpus, it may not produce sensible continuations beyond what it has seen, but we can still test that the pipeline works. For example, the prompt "Hello, how" might yield something like "Hello, how are you?" because that was in the training data.
Dockerfile and Compose for Inference:
# step2_inference_custom/Dockerfile
FROM python:3.10-slim
RUN pip install torch transformers safetensors
WORKDIR /app
COPY generate.py .
# We assume the model will be mounted at /app/model
CMD ["python", "generate.py"]# step2_inference_custom/docker-compose.yml
version: "3.8"
services:
infer_custom:
build: .
platform: linux/arm64
volumes:
- ../step1_train_custom/output_model/:/app/model # mount the trained model from step1Run this inference stage:
# In llm-pipeline/step2_inference_custom
docker-compose up --buildThe script will load the model and print out a prompt and the model's continuation. This demonstrates basic usage of the model for inference.
Caveat: Because the model and dataset are tiny, the output is likely to be trivial or repetitive. In a real scenario, you’d train on a much larger corpus. Our aim here is to confirm the end-to-end process works.
Next, we simulate updating the model with new data (Step 4). Fine-tuning uses the trained model weights as a starting point and trains further on additional data. We'll treat the small model we trained as a “pre-trained” model and fine-tune it on an updated tiny corpus.
New Fine-tuning Data: Prepare another small text file step3_finetune_custom/data/fine_tune_corpus.txt with some new content. For instance:
I am a tiny model.
I can be fine-tuned on new data.This is just to demonstrate a change. Perhaps the original model didn't see phrases like "fine-tuned on new data", so after fine-tuning, it might learn those.
Fine-Tuning Script (finetune.py): This is similar to the initial training script, but we load the existing model weights instead of initializing from scratch:
# step3_finetune_custom/finetune.py
import os
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
# Load base model and tokenizer (from mounted volume)
model_dir = "/app/base_model"
tokenizer = AutoTokenizer.from_pretrained(model_dir)
model = AutoModelForCausalLM.from_pretrained(model_dir)
# Load new fine-tuning text
data_path = "data/fine_tune_corpus.txt"
with open(data_path, 'r') as f:
new_text = f.read()
# Tokenize new text
inputs = tokenizer(new_text, return_tensors='pt')
input_ids = inputs["input_ids"]
# Move model to MPS or CPU
device = torch.device("mps") if torch.backends.mps.is_available() else torch.device("cpu")
model.to(device)
model.train()
# Simple fine-tuning loop (few epochs)
optimizer = torch.optim.AdamW(model.parameters(), lr=2e-5) # lower LR for fine-tuning
epochs = 3
for epoch in range(epochs):
optimizer.zero_grad()
outputs = model(input_ids.to(device), labels=input_ids.to(device))
loss = outputs.loss
loss.backward()
optimizer.step()
print(f"Fine-tune Epoch {epoch+1}/{epochs}, Loss: {loss.item():.4f}")
# Save fine-tuned model
os.makedirs("output_finetuned", exist_ok=True)
model.save_pretrained("output_finetuned")
tokenizer.save_pretrained("output_finetuned")
print("Fine-tuned model saved to output_finetuned/")Here we mount the original model (from Step 1) as base_model inside the container to load it. We then fine-tune on fine_tune_corpus.txt for a few epochs with a smaller learning rate. The fine-tuned model is saved to output_finetuned/.
Dockerfile and Compose for Fine-Tuning:
# step3_finetune_custom/Dockerfile
FROM python:3.10-slim
RUN pip install torch transformers safetensors
WORKDIR /app
COPY finetune.py .
COPY data/ ./data/
CMD ["python", "finetune.py"]# step3_finetune_custom/docker-compose.yml
version: "3.8"
services:
finetune_custom:
build: .
platform: linux/arm64
volumes:
- ../step1_train_custom/output_model/:/app/base_model # mount base model
- ./output_finetuned/:/app/output_finetuned # save fine-tuned modelRun fine-tuning:
# In llm-pipeline/step3_finetune_custom
docker-compose up --buildAfter it runs, check step3_finetune_custom/output_finetuned/ on your host for the updated model files. We now have a fine-tuned model in HF format.
Let's verify the fine-tuned model by doing inference again (Step 5), similar to Step 2 but loading the fine-tuned weights.
Inference Script (generate_finetuned.py):
# step4_inference_finetuned/generate_finetuned.py
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
model_dir = "/app/ft_model"
tokenizer = AutoTokenizer.from_pretrained(model_dir)
model = AutoModelForCausalLM.from_pretrained(model_dir)
model.eval()
device = torch.device("mps") if torch.backends.mps.is_available() else torch.device("cpu")
model.to(device)
prompt = "I am a tiny model"
inputs = tokenizer(prompt, return_tensors='pt').to(device)
with torch.no_grad():
outputs = model.generate(**inputs, max_new_tokens=5)
print("Prompt:", prompt)
print("Continuation:", tokenizer.decode(outputs[0]))If the fine-tuning introduced the phrase "tiny model" somewhere, the model might continue in a way reflecting the fine-tune data (for example, it might complete "I am a tiny model" with something like "... I can be fine-tuned on new data." which it saw during fine-tuning).
Docker setup for inference:
# step4_inference_finetuned/Dockerfile
FROM python:3.10-slim
RUN pip install torch transformers safetensors
WORKDIR /app
COPY generate_finetuned.py .
CMD ["python", "generate_finetuned.py"]# step4_inference_finetuned/docker-compose.yml
version: "3.8"
services:
infer_finetuned:
build: .
platform: linux/arm64
volumes:
- ../step3_finetune_custom/output_finetuned/:/app/ft_model # mount fine-tuned modelRun it with:
# In llm-pipeline/step4_inference_finetuned
docker-compose up --buildThis should print the prompt and the continuation from the fine-tuned model.
At this point, we have completed the cycle of training a custom model, saving it, doing inference, fine-tuning it, and verifying the fine-tuned version. All operations were done in Docker containers and the model is in the standard Hugging Face format in the output_finetuned folder.
Now we will proceed to model conversion and deployment steps, using the fine-tuned model we obtained. We will illustrate these steps with an example LLaMA-family model (TinyLLaMA-1.1B) since the conversion tools are largely built around LLaMA architecture models. If your custom model is not LLaMA-based, you would typically skip directly to the MLX conversion (Step 9) or only deploy it via an API. For the sake of completeness, let's proceed with the LLaMA-style path.
The GGUF format is a unified file format for LLMs introduced by the llama.cpp project. Converting a model from Hugging Face format to GGUF makes it compatible with lightweight inference engines like llama.cpp and applications that use it (e.g., text-generation-webui, LM Studio, etc.). GGUF files include model weights and metadata in a single file and support various quantization levels (Quantizing Large Language Models: A step by step example with Meta-Llama-3.1–8B-Instruct Model | by Necati Demir | Medium). This is an essential step to deploy the model using CPU or modest hardware.
For LLaMA-based models, llama.cpp provides a conversion script. We will use the fine-tuned model (if LLaMA-based) or demonstrate with TinyLLaMA for compatibility. TinyLLaMA is a small 1.1B parameter model based on LLaMA architecture (TinyLlama: An Open-Source Small Language Model - arXiv), which we can imagine as our fine-tuned model for this step.
Conversion Script (convert_to_gguf.py): We will use llama.cpp's convert_hf_to_gguf.py. To get it, we can include llama.cpp in our Docker image or download the script. E.g., clone llama.cpp and use the script directly.
Steps in the container:
1. Install llama.cpp dependencies (transformers, safetensors, etc.).
2. Download or locate the Hugging Face model to convert. If converting the fine-tuned model from Step 3, it's in a local folder. If using TinyLLaMA, we can use Hugging Face Hub.
3. Run the conversion script to produce a .gguf file.
We'll exemplify converting TinyLLaMA 1.1B (assuming it’s available as TinyLlama-1.1B on Hugging Face):
# step5_convert_gguf/convert_to_gguf.py
import subprocess
# Parameters
hf_model_name = "TinyLlama-1.1B" # huggingface model (change to local path if needed)
output_path = "model-f16.gguf" # output GGUF file (FP16 full precision)
# Note: We will quantize later, so here we keep full precision.
# Clone llama.cpp (if not already in image)
subprocess.run(["git", "clone", "--depth", "1", "https://github.com/ggerganov/llama.cpp.git"], check=True)
# Install requirements for conversion
subprocess.run(["pip", "install", "transformers", "safetensors"], check=True)
# Run the conversion script
conv_script = "llama.cpp/convert_hf_to_gguf.py"
subprocess.run(["python", conv_script, hf_model_name, output_path], check=True)
print(f"Conversion to GGUF completed: {output_path}")This script uses the command-line invocation of convert_hf_to_gguf.py. If hf_model_name is a name on the Hugging Face Hub (like TinyLLaMA), the script will automatically download the model; if it’s a path (like "/app/ft_model" for your fine-tuned custom model), it will load from there. The output is model-f16.gguf in FP16 precision (default behavior).
Note: The convert script auto-detects model architecture (supports LLaMA 1 & 2, Mistral, etc.). If you attempt to convert a model architecture it doesn't support, it will error out. TinyLLaMA is LLaMA-based, so it's supported. If you wanted to convert your custom tiny GPT2 model (which is not LLaMA), llama.cpp’s script would not work, so you would skip this step for that model and directly use MLX or another deployment.
Dockerfile for Conversion:
# step5_convert_gguf/Dockerfile
FROM python:3.10-slim
# We will need git to clone llama.cpp
RUN apt-get update && apt-get install -y git && rm -rf /var/lib/apt/lists/*
WORKDIR /app
COPY convert_to_gguf.py .
CMD ["python", "convert_to_gguf.py"]docker-compose.yml:
version: "3.8"
services:
convert_gguf:
build: .
platform: linux/arm64
volumes:
- ../step3_finetune_custom/output_finetuned/:/app/ft_model # if using local fine-tuned model
- ./output_gguf/:/app # output directory for GGUFIn the above compose, we mount the fine-tuned model (if we intended to convert it) and mount an output directory. The convert_to_gguf.py as written will output model-f16.gguf to /app which is mounted to output_gguf on host.
Run the conversion:
# In llm-pipeline/step5_convert_gguf
docker-compose up --buildAfter completion, you should have a file step5_convert_gguf/output_gguf/model-f16.gguf (around a few GB for a 1.1B model in FP16).
To confirm, the script's output or logs will indicate success. GGUF is now the container for our model weights and metadata. Next, we'll reduce its size via quantization.
Quantization compresses the model by using lower-bit representations for the weights (e.g., 4-bit or 5-bit), significantly reducing memory and storage at a minor cost to accuracy (Quantizing Large Language Models: A step by step example with Meta-Llama-3.1–8B-Instruct Model | by Necati Demir | Medium). llama.cpp supports multiple quantization schemes (Q40, Q4K, Q50, Q5K, etc.). We will use its llama-quantize tool to create a quantized GGUF model (Step 7).
Quantization Process: We have the model-f16.gguf from the previous step. We will produce, say, a 4-bit model (model-q4_0.gguf). The llama-quantize command syntax is:
./llama.cpp/llama-quantize input.gguf output.gguf q4_0Where q4_0 is one quantization type (you could choose q5_0, q8_0, etc., depending on desired trade-off). We will automate this in a simple shell script inside the container.
Quantization Script (quantize.sh):
#!/bin/bash
set -e
INPUT_PATH="model-f16.gguf"
OUTPUT_PATH="model-q4_0.gguf"
QUANT_TYPE="q4_0"
# Ensure llama.cpp repo is present (we can copy it from previous stage or clone again)
if [ ! -d "llama.cpp" ]; then
git clone --depth 1 https://github.com/ggerganov/llama.cpp.git
make -C llama.cpp -j $(nproc) # build the tools (including llama-quantize)
fi
# Run quantization
llama.cpp/llama-quantize "$INPUT_PATH" "$OUTPUT_PATH" "$QUANT_TYPE"
echo "Quantization complete: $OUTPUT_PATH"We clone and build llama.cpp (this compiles native C++ binaries; since our container is linux/arm64, it will build an Apple Silicon compatible binary). Then we run the quantizer. After running, model-q4_0.gguf will be the quantized model file. It should be much smaller (for a 1.1B model, 4-bit quantization might yield ~25% of the 16-bit size).
Dockerfile:
# step6_quantize_gguf/Dockerfile
FROM buildpack-deps:bullseye as builder # include tools for build
WORKDIR /app
COPY quantize.sh .
RUN chmod +x quantize.sh
CMD ["./quantize.sh"]We use buildpack-deps (which has build tools like make, gcc) since we need to compile llama.cpp.
docker-compose.yml:
version: "3.8"
services:
quantize:
build: .
platform: linux/arm64
volumes:
- ../step5_convert_gguf/output_gguf/:/app # mount the directory containing model-f16.gguf
- ./output_quant/:/app # output (will contain model-q4_0.gguf)Run quantization:
# In llm-pipeline/step6_quantize_gguf
docker-compose up --buildAfter this finishes, check step6_quantize_gguf/output_quant/model-q4_0.gguf. We have now a quantized 4-bit model ready for use with llama.cpp-compatible software.
Ollama is an open-source tool that makes it easy to run local LLMs (with a focus on Mac). It can directly serve models in GGUF format, providing a nice interface (CLI or API) for prompting them. In this step, we’ll import our quantized GGUF model into Ollama and run a test prompt (Step 8).
First, ensure Ollama is installed on your Mac (e.g., via Homebrew: brew install ollama). Ollama runs as a service on macOS and manages model runtimes.
To import a custom model, Ollama uses a Modelfile (similar to a Dockerfile, but for models). We will create a Modelfile in step7_ollama_deploy/ that tells Ollama where to get the model.
Modelfile example:
# step7_ollama_deploy/Modelfile
FROM ./model-q4_0.ggufThis means the model is provided by a local GGUF file (which we will place in this directory). We will copy model-q4_0.gguf from the previous step’s output into step7_ollama_deploy/ (or mount it). Alternatively, we could reference an absolute path, but copying keeps it self-contained.
With the Modelfile ready, we use Ollama’s CLI to create the model:
ollama create tinyllama-q4This command should be run in the step7_ollama_deploy directory (where the Modelfile is). It will register a model named "tinyllama-q4" with Ollama. Ollama will verify the file and set up the model.
Once created, you can run prompts:
ollama run tinyllama-q4 -p "Hello, how are you?"This will invoke the model and print its response. (The -p flag provides a prompt string).
Alternatively, use the interactive mode:
ollama chat tinyllama-q4to enter a REPL-like chat with the model.
Docker Note: We typically run Ollama on the host Mac rather than inside Docker, because Ollama is designed to interface with macOS (it uses the local system's resources and acceleration). Therefore, we do not need a Docker container for Ollama itself. We have listed step7_ollama_deploy/docker-compose.yml just for completeness (it might not be needed). In practice, once you have the .gguf file, you use Ollama directly on the Mac. (If you wanted, you could create an Ollama container, but that’s beyond our scope and usually unnecessary).
References: Ollama’s documentation confirms that you can import a GGUF model by creating a Modelfile with a FROM /path/to/model.gguf and then running ollama create <model_name> (ollama/docs/import.md at main · ollama/ollama · GitHub) (ollama/docs/import.md at main · ollama/ollama · GitHub). After that, ollama run <model_name> will use the imported model.
The final step is to convert our model into a format optimized for Apple Silicon using Apple’s MLX framework (Step 9). MLX is an array-based machine learning framework by Apple, with Python bindings (mlx-lm for language models) that allows running models with high efficiency on Mac GPUs (and even the Neural Engine in some cases) (Apple Open Source) (LM Studio 0.3.4 ships with Apple MLX). Converting to MLX format can significantly speed up inference on Mac hardware, as demonstrated by integration in tools like LM Studio.
We will use the mlx-lm Python package to perform the conversion. The mlx_lm.convert utility can take a Hugging Face model and produce an MLX checkpoint, optionally quantizing it. MLX format models can then be loaded with mlx_lm.load() and run on device.
Conversion Script (convert_to_mlx.py):
# step8_convert_mlx/convert_to_mlx.py
import mlx_lm
# Path or name of HF model to convert.
hf_model_path = "/app/ft_model" # using the fine-tuned model from Step 3 as an example
output_dir = "/app/mlx_model" # where to save the MLX-converted model
# Convert the model to MLX format with quantization
mlx_lm.convert(
hf_path=hf_model_path,
mlx_path=output_dir,
quantize=True # enable quantization (by default, MLX uses 4-bit quantization for supported models)
)
print("MLX conversion complete. Saved to:", output_dir)The mlx_lm.convert function will handle downloading the model if hf_path is a Hub name, or use the local directory if given. We set quantize=True to compress the model (this often produces a ~4-bit weight precision model, similar to what we saw in the MLX example on HuggingFace (mlx-community/Llama-3.2-3B-Instruct-4bit · Hugging Face)). After this, mlx_model/ will contain files like model.safetensors, config.json, etc., in a format that mlx_lm expects. (It often still uses safetensors, but weights are arranged for MLX).
Dockerfile and Compose:
# step8_convert_mlx/Dockerfile
FROM python:3.10-slim
RUN pip install mlx-lm==0.21.5 # specify a version known to work
WORKDIR /app
COPY convert_to_mlx.py .
CMD ["python", "convert_to_mlx.py"]# step8_convert_mlx/docker-compose.yml
version: "3.8"
services:
convert_mlx:
build: .
platform: linux/arm64
volumes:
- ../step3_finetune_custom/output_finetuned/:/app/ft_model # mount HF model (fine-tuned)
- ./mlx_model/:/app/mlx_model # output MLX model directoryRun the conversion:
# In llm-pipeline/step8_convert_mlx
docker-compose up --buildAfter completion, check step8_convert_mlx/mlx_model/. You should see the converted model files (the directory structure and file names might resemble a HuggingFace model, but the weights are now optimized/quantized for MLX).
Running the MLX model: On your Mac, you can use the mlx_lm package to load and run the model. For example, in a Python REPL or script:
from mlx_lm import load, generate
model_path = "path/to/mlx_model" # the directory from conversion
model, tokenizer = load(model_path)
output = generate(model, tokenizer, prompt="Hello, how are you?", max_tokens=50)
print(output)This will use the MLX backend to execute the model. Since the model is quantized and using Apple’s optimized kernels, you should see very fast inference speeds on Mac M1/M2 (especially compared to the unoptimized PyTorch run). In fact, Apple’s MLX has shown impressive token generation rates on LLaMA-style models (Run LLMs on macOS using llm-mlx and Apple’s MLX framework).
We have now successfully converted our model into multiple formats and run it in different runtime environments: - Hugging Face Transformers (for training/fine-tuning and Python inference). - GGUF (llama.cpp) for lightweight CPU (and Metal) inference, including via Ollama which simplifies deployment. - Apple MLX format for direct, efficient execution on Apple Silicon GPUs.
coremltools) for iOS/ANE, or use MLX as we did. The MLX framework supports many architectures and is rapidly evolving (ml-explore/mlx-lm: Run LLMs with MLX - GitHub).linux/arm64. Many ML Python wheels (torch, transformers, etc.) are available for arm64 Linux. If an arm64 wheel isn’t available, you may need to compile from source or use an x86 image with Rosetta (not ideal for performance)."mps" device when available. Not all operations or datatypes are supported on MPS (e.g., bfloat16 might not be, and earlier versions had some ops missing), but basic Transformers operations should work. Always test your code on CPU as a fallback (PYTORCH_ENABLE_MPS_FALLBACK=1 can be set to automatically fall back to CPU for unsupported ops).By following this tutorial, you have containerized each stage of an LLM workflow on Apple Silicon: training a model, fine-tuning it, and deploying it in multiple optimized formats. This modular approach using Docker ensures reproducibility and separation of concerns for each step. You can now experiment with different models and datasets, confident that you can take a model from initial training all the way to efficient local deployment on your Mac. Enjoy building and deploying your own models!
Sources: