🔢 Softmax Visualizer
📘 Understanding Softmax
What Are Logits?
Logits are the raw output scores from a model’s final layer — before applying any transformation. They represent unnormalized confidence levels for each option or class.
What Is Softmax?
The softmax function transforms logits into probabilities that sum to 1. It allows the model to express confidence for each class in a probabilistic way.
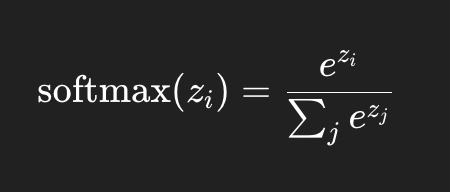
Each value is exponentiated, then divided by the sum of all exponentiated values — making the outputs valid probabilities.
Why Normalization?
Normalization ensures that outputs are meaningful probabilities, helping models make interpretable and fair decisions.
What Is Numerical Stability?
To avoid overflow/underflow from large exponentials, we subtract the maximum logit before computing softmax. This doesn't change the result, but it prevents errors.
Tip: Always compute softmax as exp(logits - max(logits))
Softmax is a function that converts a list of numbers (logits) into a probability distribution. It’s widely used in classification problems and attention mechanisms in neural networks.
🔢 What Softmax Actually Does
- Normalizes raw outputs so that each value is between 0 and 1.
- The sum of all outputs is exactly 1 — allowing interpretation as probabilities.
- Amplifies relative differences between values — larger inputs dominate the output.
Example: For inputs [2.0, 1.0, 0.1], softmax outputs roughly:
[0.65, 0.24, 0.11]
These probabilities sum to 1.
🎯 Key Properties
- Output Sum = 1: Required for probabilistic interpretation.
- Amplification Mechanism: A small absolute difference becomes a large probability difference. Example: [10, 9, 9] → [0.84, 0.08, 0.08]
🌡️ Temperature Scaling
You can control the sharpness of softmax with a temperature parameter (T):
softmax(xᵢ) = e^(xᵢ / T) / ∑ e^(xⱼ / T)
- Low T (e.g., 0.5): Sharper, more confident probabilities.
- High T (e.g., 2.0): Softer, more spread-out probabilities.
✅ When to Use Softmax
- ✅ Multi-class classification (final layer in DNNs)
- ✅ Attention mechanisms in transformers
- ❌ Not for binary classification (use sigmoid instead)
- ❌ Not for regression problems
⚠️ Common Mistake: Manual Softmax Before CrossEntropyLoss
In frameworks like PyTorch:
loss = nn.CrossEntropyLoss()(logits, targets) # DO NOT apply softmax manually
Softmax is already applied internally in CrossEntropyLoss for numerical stability. Applying it manually will lead to incorrect training.
✅ Softmax outputs are probabilities between 0 and 1, and they always sum to 1.
✅ It amplifies relative differences, giving more confidence to higher logits.
🚀 Use it for classification tasks — but don’t apply it manually if your loss function already includes it.